LongRoPE: Tool for Extending LLM Context Windows
Project Overview
| GitHub Stats | Value |
|---|---|
| Stars | 120 |
| Forks | 11 |
| Language | Python |
| Created | 2024-03-06 |
| License | - |
Introduction
LongRoPE is a innovative method designed to extend the context window of large language models (LLMs) significantly beyond the current limits. This project focuses on overcoming the traditional constraints of LLMs, which are typically limited to processing a few thousand tokens at a time. By identifying and exploiting non-uniformities in positional embeddings, LongRoPE enables an 8x extension of the context window without the need for fine-tuning. It also employs an efficient progressive extension strategy to reach contexts as large as 2 million tokens with minimal fine-tuning. This advancement is crucial for improving the performance of LLMs in various natural language processing tasks, making it worth exploring for anyone interested in enhancing text generation and context understanding capabilities.
Key Features
The LongRoPE project introduces a method to extend the context window of large language models (LLMs) beyond 2 million tokens, addressing the limitations of traditional Transformer architectures. Key features include:
- Progressive Extension Strategy: Incrementally fine-tuning the model to handle longer contexts, starting from 256k tokens.
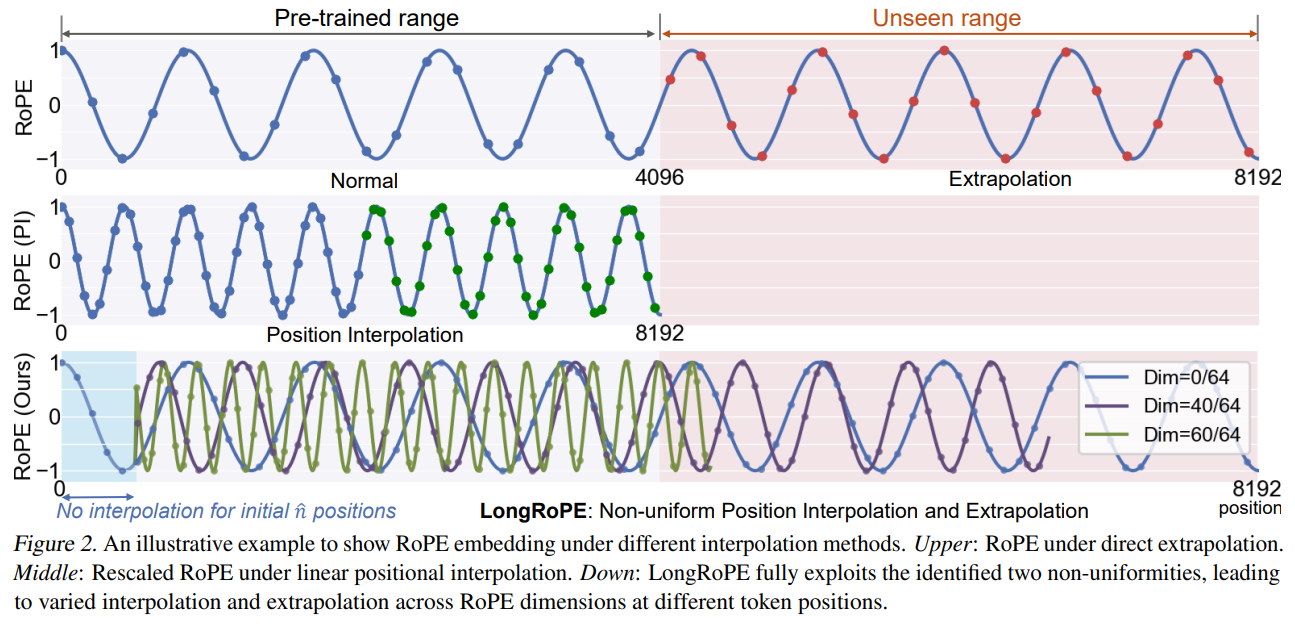
- Positional Embeddings Adjustment: Exploiting non-uniformities in Rotary Positional Embeddings (RoPE) to minimize information loss during interpolation.
- Performance Maintenance: Adjusting embeddings to recover performance in shorter contexts.
- Applications: Suitable for in-context learning, long document summarization, and few-shot learning, maintaining low perplexity and high accuracy across various context lengths.
Real-World Applications
In-Context Learning: LongRoPE can be used to enhance in-context learning by providing large language models (LLMs) with more examples to boost their reasoning capabilities. For instance, you can extend the context window to include multiple examples of a task, allowing the model to learn from a broader set of inputs.
Dialog and Question Answering: Build LLM agents that leverage longer contexts for tasks like dialog and question answering. This can improve the model’s ability to understand and respond to complex queries by considering a larger portion of the conversation history.
Long Document Summarization: Utilize LongRoPE to summarize very long documents by processing the full document context. This is particularly useful for tasks where understanding the entire document is crucial, such as legal or academic texts.
Few-Shot Learning: Enhance few-shot learning by providing more contextual examples to the model. With a larger context window, the model can learn from fewer examples and generalize better to new tasks.
Long-Term Memory: Enable long-term memory in LLMs by utilizing the full context window. This allows the model to retain information from earlier parts of the input sequence, which is beneficial for tasks that require remembering details over long periods.
Exploring and Benefiting from the Repository
- Custom Dataset Training: Train LongRoPE on your custom dataset by preparing your data in a compatible format and using the
extend_contextmethod. - Hyperparameter Tuning: Tune key hyperparameters such as
population_size,num_mutations, andnum_crossoversto optimize the model’s performance. - Advanced Usage: Use the provided code snippets and documentation to implement advanced features like layer scaling, memory management, and token-wise attention mechanisms.
- Evaluation Metrics: Evaluate the model’s performance using metrics like perplexity, accuracy, and passkey retrieval accuracy to ensure it meets your requirements.
By leveraging these features, users can significantly enhance the capabilities of their LLMs, enabling them to handle complex tasks that require extended context windows.
Conclusion
The LongRoPE project significantly extends the context window of large language models (LLMs) to over 2 million tokens, addressing a major limitation of traditional Transformer architectures. Here are the key points:
- Context Extension: LongRoPE uses a progressive extension strategy and adjusts Rotary Positional Embeddings (RoPE) to minimize information loss, enabling an 8x context extension without fine-tuning.
- Performance: The method maintains low perplexity and high accuracy across context lengths from 4k to 2048k tokens, making it suitable for tasks like in-context learning, long document summarization, and few-shot learning.
- Applications: Potential uses include enhancing LLM reasoning, building agents for dialog and question answering, and improving long-term memory in LLMs.
- Efficiency: The approach avoids direct fine-tuning on extremely long texts, reducing computational costs and leveraging a search algorithm to optimize performance for shorter contexts.
Overall, LongRoPE enhances the capabilities of LLMs by handling much longer contexts, opening up new possibilities in natural language processing.
For further insights and to explore the project further, check out the original jshuadvd/LongRoPE repository.
Attributions
Content derived from the jshuadvd/LongRoPE repository on GitHub. Original materials are licensed under their respective terms.
Stay Updated with the Latest AI & ML Insights
Subscribe to receive curated project highlights and trends delivered straight to your inbox.