ArXiv ChatGuru: Interactive RAG Tool for Scientific Literature
Project Overview
| GitHub Stats | Value |
|---|---|
| Stars | 521 |
| Forks | 69 |
| Language | Python |
| Created | 2023-02-10 |
| License | MIT License |
Introduction
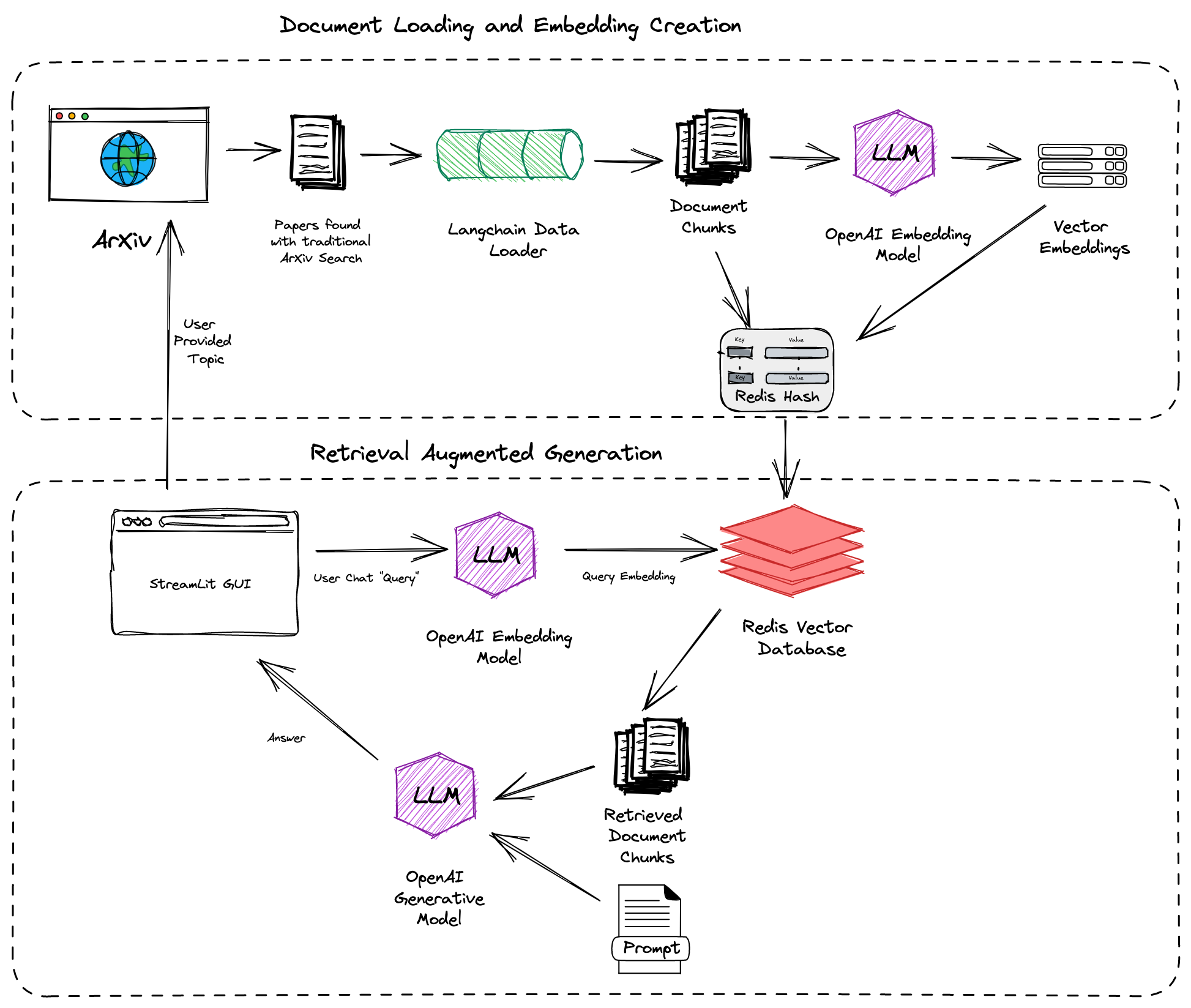
ArXiv ChatGuru is a tool designed to make the vast collection of scientific papers on ArXiv more interactive and accessible. Using LangChain and Redis, it enables users to engage with research in a more engaging way. Here’s how it works: users submit a topic, and the system retrieves relevant papers from ArXiv, chunks them into smaller pieces, generates embeddings, and stores these in a Redis vector database. Users can then ask questions about the retrieved papers, and the system provides the most relevant answers. This project not only simplifies accessing research but also educates on Retrieval Augmented Generation (RAG) systems.
Key Features
ArXiv ChatGuru is a tool designed to make the vast collection of scientific papers on ArXiv more interactive and accessible. Here are its main features and capabilities:
How it Works
- Users submit a topic, and the system retrieves relevant papers from ArXiv.
- These papers are chunked into smaller pieces, and embeddings are generated and stored in Redis.
- Users can ask questions about the retrieved papers, and the system returns the most relevant answers.
Components
- LangChain’s ArXiv Loader: Pulls scientific literature directly from ArXiv.
- Chunking + Embedding: Segments papers into manageable pieces and generates embeddings using LangChain.
- Redis: Used for fast and efficient vector storage, indexing, and retrieval.
- RetrievalQA: Allows users to query papers using LangChain’s RetrievalQA and OpenAI models.
- Python Libraries: Utilizes tools like
redisvl,Langchain, andStreamlit.
Learning Outcomes
- Context Window Exploration: Understands the impact of context window size on interaction results.
- Vector Distance Insights: Shows the role of vector distance in context retrieval for RAG systems.
- Document Retrieval Dynamics: Observes how the number of documents retrieved affects RAG system performance.
- Using Redis as a Vector DB and Semantic Cache: Teaches how to use Redis for RAG systems.
Note
This is a learning tool rather than a production application, designed to help users understand how Retrieval Augmented Generation (RAG) systems work. It is built using Streamlit for easy interaction.
Real-World Applications
Exploring Scientific Literature
- Topic-Based Search: Users can submit a specific topic to retrieve relevant scientific papers from ArXiv. For example, if you are interested in “quantum computing,” the system will fetch and process papers related to this topic, allowing you to ask questions about the content.
Interactive Q&A
- Question Answering: After retrieving papers on a topic, users can ask specific questions about the content. For instance, if you retrieved papers on “climate change,” you could ask “What are the main causes of climate change?” and the system will provide an answer based on the retrieved papers.
Educational Use Cases
- Understanding RAG Systems: The tool is designed to teach users about Retrieval Augmented Generation (RAG) systems. Students and researchers can explore how context window size, vector distance, and document retrieval dynamics affect the performance of RAG systems.
Technical Learning
- Using Redis as a Vector Database: Users can learn how to use Redis for efficient vector storage, indexing, and retrieval in the context of RAG systems. This includes understanding how to use Redis as a semantic cache.
Benefits for Users
- Enhanced Accessibility: Makes scientific literature more interactive and easier to understand.
- Educational Insights: Provides hands-on learning about RAG systems and their components.
- Customizable Interactions: Allows users to explore different parameters such as context window size and vector distance to see their impact on the system’s performance.
Running the App
To start using ArXiv ChatGuru, you can either run it locally or use Docker Compose. Here are the basic steps:
Run Locally
- Clone the repository.
- Create and fill out the
.envfile with necessary API keys. - Install dependencies using
pip install -r requirements.txt. - Run the app with
streamlit run App.pyand navigate tohttp://localhost:8501/.
Docker Compose
- Clone the repository.
- Create and fill out the
.envfile. - Run the app using
docker compose upand navigate tohttp://localhost:8080/.
This setup allows users to interact with the tool easily and explore its various features.
Conclusion
Impact:
- Enhanced Accessibility: Makes ArXiv’s scientific papers more interactive and easier to understand.
- Educational Value: Teaches about Retrieval Augmented Generation (RAG) systems and their components.
- Efficient Retrieval: Utilizes Redis for fast vector storage and retrieval.
Future Potential:
- Improved Filtering: Plans to add filters for year, author, etc.
- Efficiency Enhancements: Aims for more efficient chunking and embedding processes.
- Conversational Memory: Intends to implement chat history and conversational memory with LangChain.
- Scalability: Although not currently production-ready, it has the potential to be scaled up with further development.
For further insights and to explore the project further, check out the original redis-developer/ArXivChatGuru repository.
Attributions
Content derived from the redis-developer/ArXivChatGuru repository on GitHub. Original materials are licensed under their respective terms.
Stay Updated with the Latest AI & ML Insights
Subscribe to receive curated project highlights and trends delivered straight to your inbox.